Once upon a time I listened to a talk with this title, given by a CFO of a multi-national service provider.
The intention was to measure activity, cost, and revenue across a sprawling estate so that better decisions could be taken.
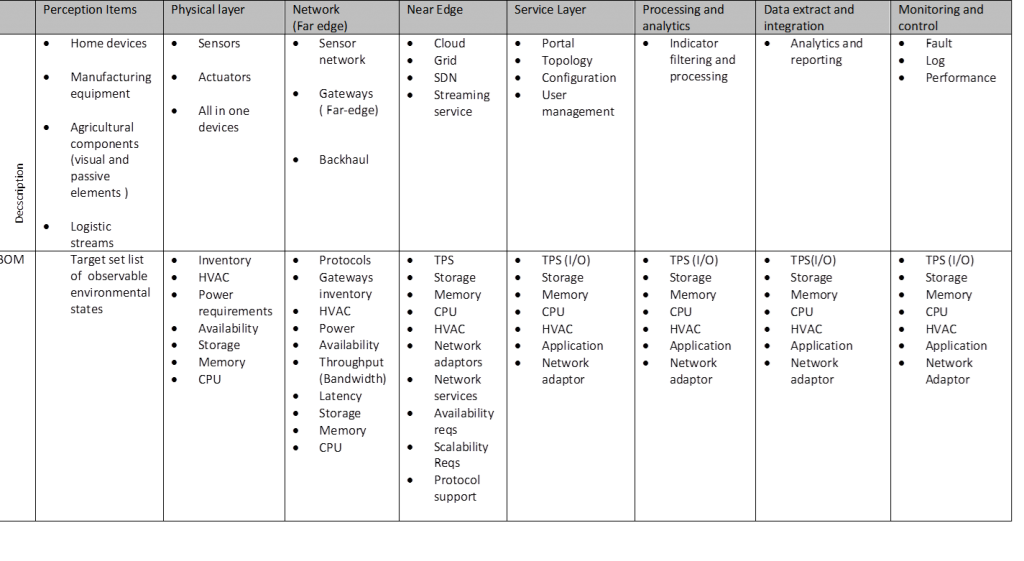
Over ten years later and with additional experience of the challenges operators face in addressing so called “digital” initiatives the very subject has come back to mind. The following three risks directly related to measurement have not been addressed presenting an obstacle in decision making and monetization.
- Lack of performance measurement to drive execution
- Failure to understand what customers value
- Inability to extract value from network assets
In fact, with certain exceptions, there is no clear understanding of value flow across an operating company. CSP’s do not measure value across the operation, and towards their customers, despite the hard work done by the teams in each vertical domain, and in quantifying the heavyweight procurement decisions which are necessary in large scale network rollout and the like. Clearly this is not enough. Joining up the dots is optional.
Informed operators are seeking business decision making support through tools, methods and processes and a thriving consulting business has developed around that. However the nature of the organizational divide across the enterprise preempts visibility, maintaining well known vertical cost centers and spheres of influence. At the same time nimble integrated companies flourish by eating the whale’s dinner, or rather it can be said that as trusted partners their competitive advantage and comparative margin is higher, than that of the host.
The operator’s response has been to throw technology at the perceived problem, initiate high-end, long duration transformation programs, encouraged by vendors, and reduce staffing through outsourcing and other means.
Most of these attempts have failed to deliver the expected value, resulting in increased inertia and complexity with corresponding increase in operating cost in the short term and reduced ROI overall.
On the other hand agility has been touted as a solution for optimizing demand & supply without taking into account the value which such an approach will bring, given business, organizational and technical requirements and constraints.
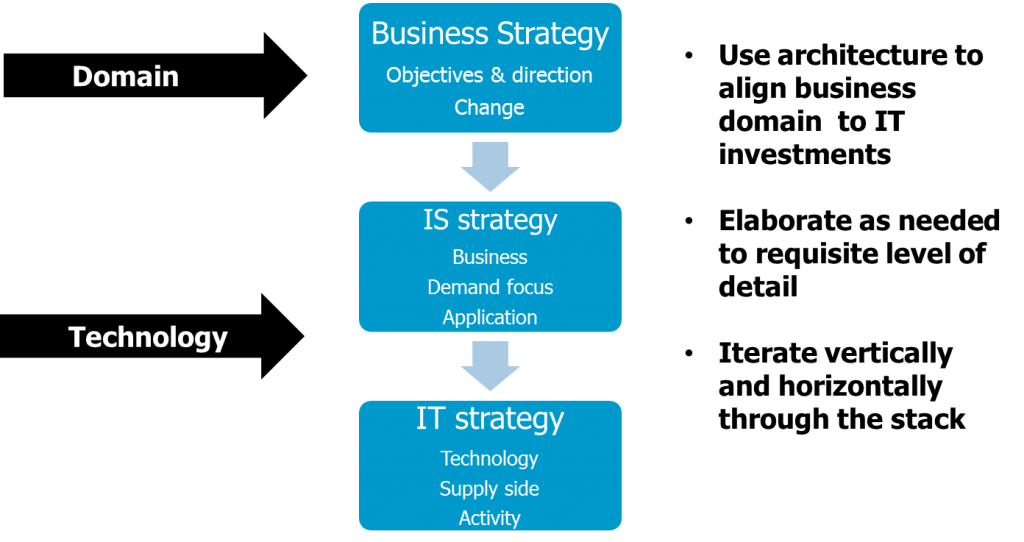
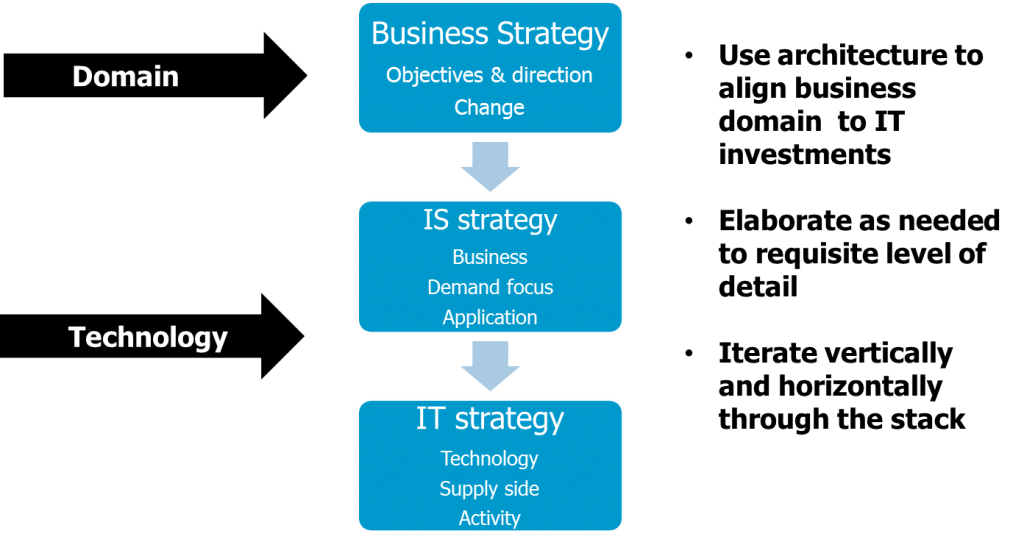
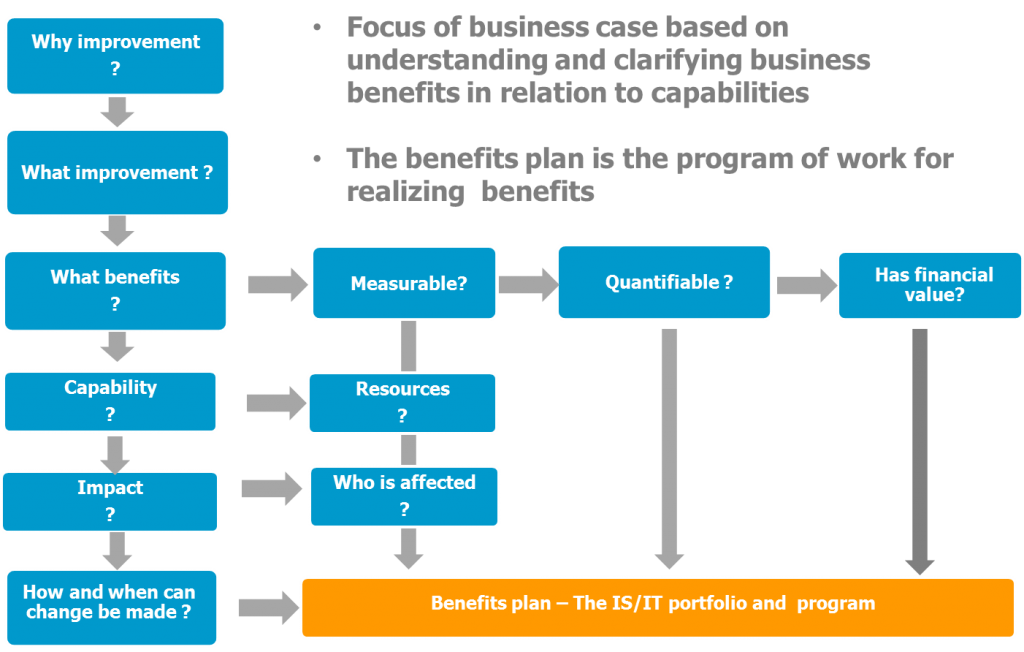
I’m suggesting that in order to progress change through a service provider organization the first step would be to identify the value proposition, at a moment in time and in the foreseeable future together with all the variables of uncertainty.
Value can be mapped to investment objectives, and these in turn to current and future operating models, right down to the technology enablers. In doing so there is a great deal of scope for exercising both left and right brain capabilities in planning and innovation across a group of people, the stakeholders.
Smart and nimble integrated companies know this and start with a small core team, well established value drivers, a flexible partner strategy and a clear technology differentiator. Once those principles are established brand and capability will follow.
The point I’m trying to make is that by starting with an understanding of core business value as whole and individually, an operator may improve their key strengths (And identify areas of improvement ) rather than seeking to leverage arbitrary value creating initiatives, competing with global portfolios of standardized and established products.
In doing so they can begin to make the necessary internal changes to support increasing levels of automation, and supporting research and development, changes which do not fit neatly into the established vertical functions established over twenty years ago.
The consumer does not care if a product is sliced and diced in a myriad ways, they want a simple, effective, easily understood offer, one which always works everywhere, and for which there are no surprises.
Adding “digital” complexity to the customer experience just adds costs and frustration, without fundamentally improving the user experience, there are products which do this and do it well, and quite frankly keeping up with these is a lost cause.
As for the silver bullet presented by cloud & virtualization while these may reduce complexity on one level, and promote effectiveness, they shift the work elsewhere. Cloud is an improvement tool not a solution to the key problem of gaining value, effectiveness, and efficiency from existing and new assets while delivering a world class service.
One may argue that this concept of value realization is not restricted to service provider operators alone (We can call them Telco’s, it’s ok ) it is part and parcel of any digital business, but the challenges which Telco’s face are unique in that there is an established order, and a regulatory framework ,which must be overcome and influenced before value and revenue is gained through innovation and automation.
The very word “digital” is misleading in that Telco’s led the way in digital capability from the get go, they are already digital and highly capable in delivering an adequate service to millions of subscribers, albeit poorly integrated. M2M has been implemented by Telco’s over 20 years ago and the prime invention of caller identification which set the stage for telephony based services in 1968. The implications of this were huge, for example leading to a range of applications in secure authentication for all sorts of applications, including banking.
This invention, and innumerable others did not occur in a vacuum, or a rigid shareholder driven environment they were fostered by a well-funded integrated partnership between research and industry, scaling across many different organizational silos and interests. But we are speaking of history.
So the second step is to revert to the original ecosystem framework, drop the silos, the organizational structures which did so well in terms of process engineering, specialization, and skills development in the recent past, directly contributing to organizational inertia in the present, and perpetuating the view that as long as our department performs it’s someone else’s responsibility to address the customers complaints, fix faults, or provide replacement modems on time.
As seen from a current perspective Telco is a production line, which can be largely automated, with a healthy Marketing and R&D component, skills can and should be interchangeable and transferrable, with some notable exceptions, and new skills are required to invent and run the latest technologies effectively. We need to formalize an experimental inventive mode while doing solid production engineering, and find the funds to do it with. It will help if we know and can measure what we have and what we want in doing so.
In summary:
- Identify and measure value collaboratively within and externally to the organization
- Set up the investment plan according to capability with clearly defined metrics
- Include an R&D and investment budget
- Plan and initiate research and development, or find a partner who can
- Track performance across the organization
- Increase and extend capability through internal skills development and external ecosystems
- Drop the silos and clarify the new organization
- Run the programs
- Measure results on an ongoing basis on a common framework